The Internet’s Lost Lessons: Deploying AI to Restore Trust and Knowledge
As organisations prepare to deploy AI, a rare opportunity emerges: to restore Internet-era principles—openness, decentralisation, and edge intelligence—reclaiming coherence, control, and meaning in their data, and activating institutional knowledge with intention.

TL;DR
The Internet’s foundational principles — openness, decentralisation, interoperability, and intelligence at the edges — made it a platform for permissionless innovation and collaboration. But as organisations migrated to cloud-based ERPs, CRMs, and other managed platforms, much of their institutional knowledge became fragmented, enclosed within proprietary systems, and governed by external logic. Vendor-driven architectures disrupted internal coherence, while siloed data flows eroded institutional memory. Today, as organisations navigate the deployment of AI — whether through cloud, hybrid, or on-premises models — they face a rare opportunity to reverse that drift. In our previous post, we explored this spectrum of deployment choices, highlighting that the decision is not binary but strategic. By intentionally applying the Internet’s original principles — openness, interoperability, and decentralised reasoning — to AI system design, organisations can reclaim control, re-integrate their data, and build intelligent systems aligned with their values, governance models, and ways of reasoning.
This post has four sections. It starts by looking back at the Internet's foundational ideals — openness, decentralisation, and end-to-end intelligence — and investigates how these values may guide a more deliberate strategy to deploy AI. The second part addresses the practical challenge of preparing data for deployment, arguing that this is a non-delegable responsibility for organisations seeking to activate their institutional knowledge. It offers use case categories to guide organisations on where AI may assist with their operations. From there, the post looks at developing architectures for context-sensitive, privacy-preserving, and decentralised AI. Its last section includes a values-led decision framework to help organisations decide when and how to use AI ethically and in line with their mission.
Introduction
The rise of AI presents a powerful opportunity: for organisations to reclaim ownership of their data — not just as an operational asset, but as a reflection of their values and institutional knowledge.
The Internet was founded on a radical promise: open, non-proprietary protocols; decentralised architecture with no single point of control; and the end-to-end principle, where intelligence resided at the edges, not the core. These weren’t just technical choices — they were ideological ones. They enabled permissionless innovation, safeguarded user autonomy, and fostered a generative commons where collaboration could thrive across borders.
Yet, in the pursuit of efficiency and scale, the rise of cloud computing began to challenge the Internet’s original architecture.
Over time, critical organisational knowledge became embedded in cloud-based CRMs, ERPs, document repositories, and proprietary platforms — each powerful in isolation, but increasingly detached from the institutional logic that produced them. Control shifted toward managed infrastructures. Although cloud services brought elasticity and uptime that few could build in-house, they also introduced middle-agents, enclosed ecosystems, and opaque dependencies that compromised the Internet’s original principle of decentralised agency.
Then came AI.
Large Language Models (LLMs), Retrieval-Augmented Generation (RAGs), and now agentic AI architectures have the potential to accelerate centralisation. Often deployed through cloud infrastructure, these systems can ingest vast volumes of institutional and user data — learning from behaviour, embedding black-box logic into critical workflows, and shaping decisions in ways that may elude scrutiny. While they offer significant capabilities, they also raise concerns around sovereignty, interpretability, and epistemic control.
But this doesn’t need to be inevitable.
As security, privacy, and intellectual property concerns catch up with the promise of AI, sovereign AI stacks are emerging that are modular, local, and intelligible. In response, AI is increasingly conceived not as a monolithic cloud service, but as a steward of institutional knowledge — governed by the values, language, and judgement of those who operate it.
In this sense, AI opens the door to reintegrating fragmented knowledge, restoring coherence, and activating it in ways that reflect an organisation’s unique worldview. But this is not just a technical upgrade. It’s a strategic and cultural inflection point — a moment of epistemic self-definition. A chance to articulate what an organisation considers legitimate knowledge, how it reasons, and what principles guide its actions. Training an AI system becomes a form of institutional introspection: encoding priorities, ethics, and logic into a system that not only processes information, but also interprets meaning and context. This requires thoughtful curation, deliberate governance, and clarity about whose perspectives are centred, what narratives are privileged, and what trade-offs are acceptable.
In doing so, organisations reconnect not only with their identity but with the foundational principles that made the Internet transformative: openness, decentralisation, interoperability, and end-to-end agency. These design choices empowered innovation at the edges, preserved the freedom to connect, and prevented control from consolidating at the centre. Those same ideals are just as relevant to AI today; they protect against silos, allow cross-border cooperation, and guarantee that intelligence stays flexible, pluralistic, and in line with human values.
And here lies a vital reconciliation: data sovereignty need not to imply isolation. Even on-premises or air-gapped AI can participate in global knowledge ecosystems, through federated learning, open standards, and controlled interoperability. These systems can be local in governance, yet networked in principle, mirroring the original logic of the Internet itself.
Instead of dismissing the cloud, organisations may choose a hybrid strategy that mixes the flexibility and scalability of cloud infrastructure with the confidence of local control. Choosing when and how to connect, share, and collaborate helps them to minimise fragmentation, protect sensitive data, and stay engaged in a dynamic innovation ecosystem.
Still, only technical architecture is not enough. The deeper challenge is epistemological.
How can organisations ensure that sovereign AI systems avoid insularity? The answer lies in designing for epistemic pluralism, recognising that no one model or institution holds a monopoly on knowledge. While still being open to conversation, benchmarking, and ethical exchange, Sovereign AI must reflect local values and context. This is not about uniformity — it’s about developing systems that can run independently and interact respectfully across difference.
Seen this way, sovereign AI is not a retreat but an evolution. A way to build intelligent systems that are secure, contextual, and interoperable. Systems that respect the distinctiveness of each organisation, while contributing to the shared fabric of knowledge. This is a return to the Internet’s first principles: to empower the edges, coordinate the whole, and respect the diversity in between.
Preparing Data for AI Deployment: A Non-Delegable Responsibility
Effective AI deployment requires a clear-eyed strategy to prepare, govern, and operationalise data. This work spans three interdependent domains:
- Ethical and Strategic Foundations
Ensuring that AI outputs reflect institutional values, especially critical for agentic systems operating with limited human oversight. - Privacy and Security
Addressing the full spectrum of deployment — from public cloud to air-gapped environments — by implementing controls to prevent data leakage, regulatory breaches, or unintended disclosure through model hallucinations. - Technical Readiness and Architecture
Structuring and embedding unstructured content for machine-readability, and selecting infrastructure — on-prem or hybrid — that balances performance, governance, and control.
This is not work that can be outsourced. Much of an organisation’s knowledge sits in proprietary systems — CRMs, ERPs, HR platforms — whose data is fragmented, access-limited, or constrained by licensing or compliance. Preparing this data involves extraction, schema normalisation, pseudonymisation, semantic harmonisation, and format conversion for AI training or retrieval-augmented generation (RAG).
Modern data platforms like Snowflake help consolidate semi-structured content across systems into a single, queryable layer. From there, data can be enriched, masked, and embedded for use with vector databases like FAISS (Facebook AI Similarity Search), developed by Meta, enabling RAG pipelines via frameworks such as LlamaIndex. These technologies support curated knowledge slices with access controls, auditability, and data sovereignty built in.
Middleware pipelines—from Apache NiFi to Fivetran — can automate the flow of data — sales records, support tickets, policy documents — into structured repositories, converting them into machine-readable formats like JSON or annotated text.
Business intelligence platforms like Tableau or PowerBI can surface curated slices of institutional logic — financial summaries, compliance dashboards, or customer segmentation — that can be exported for indexing or training.
Where integration is more difficult, lightweight API wrappers or robotic process automation (e.g., UIPath) can simulate data access, while semantic layers help harmonise terminology across systems through tools like LangChain or knowledge graphs.
These are more than technical steps — they are strategic translations. AI systems can only reason as well as the data they are trained on. That data must be liberated, contextualised, and aligned with organisational logic to become a reliable foundation for decision-making.
Once this groundwork is in place, domain-specific copilots and autonomous agents can emerge — integrated with CRMs, ERPs, and other internal tools to activate institutional knowledge across legal, customer support, and operational workflows. Powered by open-source frameworks such as Hugging Face for language modeling and FAISS for fast semantic retrieval, these systems do more than respond to queries—they synthesise fragmented data, interpret organisational context, and convert static information into dynamic, actionable intelligence.
In effect, the organisation’s own context becomes part of the AI’s reasoning layer, ensuring outputs that are not only fluent but grounded in operational reality. This approach offers a powerful balance between performance and control — embedding intelligence while preserving data integrity, security, and institutional sovereignty.
Use case summary
The following chart helps organizations evaluate how AI can support different functions by mapping use cases across a spectrum of autonomy. Each category—assistive, adaptive, and agentic—represents a distinct level of initiative and integration, from basic task support to systems capable of pursuing goals independently. For any AI strategy to be effective, it’s essential to clarify not only where AI can add value, but also to what extent: should the system assist, respond to context, or take initiative?
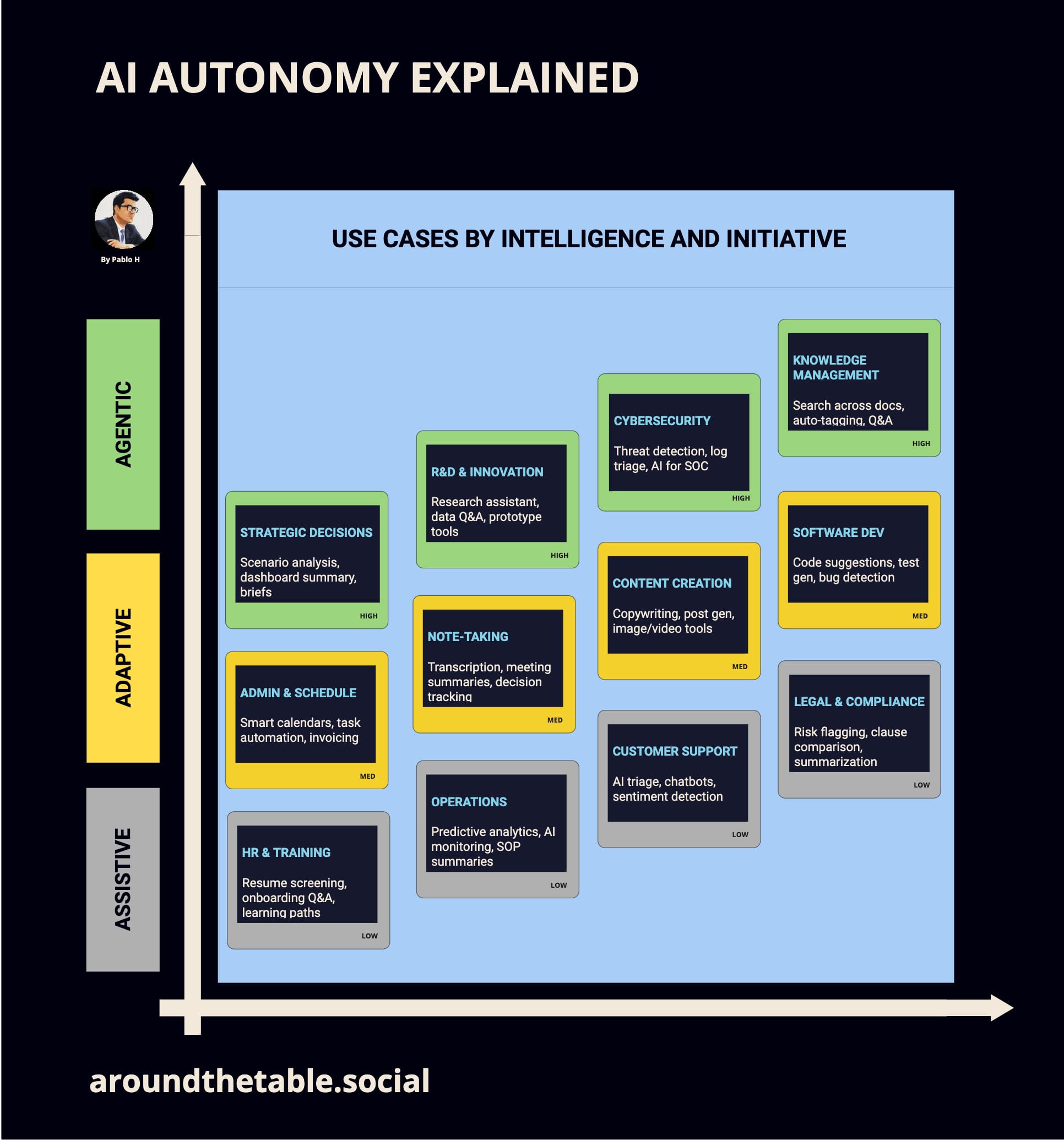
In the context of this table, agentic AI refers to systems that can act autonomously or semi-autonomously toward a goal — initiating actions, adapting to context, and using tools to complete multi-step tasks with minimal human prompting. By contrast, assistive AI is reactive, providing outputs in response to specific inputs without broader initiative. Some use cases are labeled adaptive or context-dependent because their classification depends not on the use case itself, but on how the AI is implemented — for example, a customer support system could simply answer queries (assistive) or proactively triage, escalate, and follow up on tickets (agentic). The classification in the table helps to highlight where agency is either designed into the system or could be enabled with further integration.
Emerging Technologies for Trustworthy, Decentralized, and Privacy-Preserving AI
To ensure privacy, autonomy, and reduced dependence on centralised systems, a new class of AI technologies is gaining momentum:
- Federated Learning (FT), which trains models across distributed nodes without sharing raw data
- Privacy-Enhancing Technologies (PETs), like homomorphic encryption and secure multi-party computation
- Local Differential Privacy, which anonymises data at source
- Decentralised Data Governance, as explored in Gaia-X and similar initiatives
- Blockchain and Confidential Computing, which secure tamper-proof records and auditability
Together, these approaches represent a shift toward AI ecosystems that are not only powerful but also aligned with fundamental principles of autonomy, privacy, and democratic data stewardship.
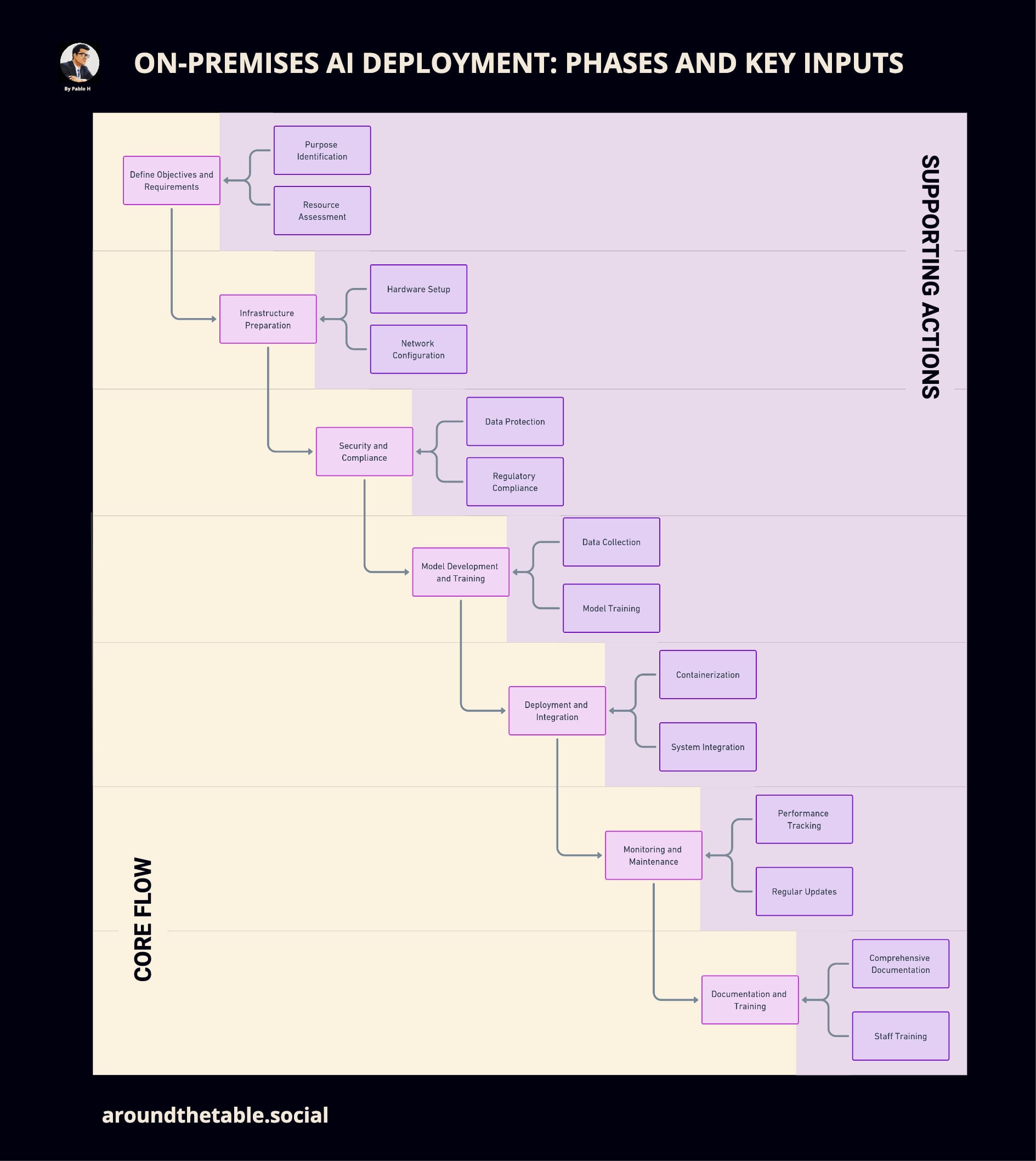
Is On-Premises AI Worth It? A Decision Framework
The following seven-step framework helps guide that reflection, moving beyond technical feasibility to examine control, trust, and institutional responsibility. Especially for sectors dealing with sensitive data, high stakes, or public accountability, this is a tool for deciding whether on-premises AI is not just viable, but appropriate.
- Define Objectives – Is AI the right tool for your goals and values?
- Infrastructure Preparation – Are you prepared to manage your own stack securely?
- Security and Compliance – Can you control data end-to-end and meet legal obligations?
- Model Development – Who shapes your AI’s logic, ethics, and behaviour?
- Deployment and Integration – Will AI enhance or disrupt your workflows?
- Monitoring and Maintenance – Can you commit to ongoing governance and ethics?
- Documentation and Training – Are you building capacity and trust internally?
Conclusion
The opportunity before us is not simply technical — it is institutional, strategic, and philosophical. AI can evolve into a steward of organisational knowledge, aligned with the governance structures and values that define each institution. But, to get there, we must design for coherence, embed intelligence in context, and preserve the openness and pluralism that once defined the Internet.
Sovereign AI is not about closing off — it’s about taking ownership. About building systems that can think with us, not for us.